This blog will be my notepad of things i learn , new programming language, tools , compilers etc.This blog is more of my penesive to see how much my understanding of things have evolved.
In this part, i will discuss how i wrote the basic url shortener, in which i will implemented a web page which returns a shortened URL. THer is no user based login stuff, no stats, no setting preffered short form and so on.Just enter the URL and the site would return a shorter version which is of fixed length of 6.
Model implementation
In the first part of this blog. i will discuss the implementation of the backend i.e database storage and retrieval.
We would want to make changes to a branch in git. We use branches to make sure that we can make group of changes independent of the main branch and merge code when its ready. So the main branch(also called master in git) is always present with a ready to ship code and we can multiple branches for each individual features.
Since we are going to write unit test in alongside code , we need to install the basic unit testing framework of python i.e pyttest.
pip install pytest
Lets now start creating a folder called models. Models in MVC architecture hold the code that does all the database handling ie all CRUD operation to the database.
$ mkdir models
$ cd models
Lets create a class(urlShortener) that performs all the operations to the database for url shortening. The class which performs the basic handling of storing to the database would look like below
class urlShortener:
def __init__(self, collection):
self.collection = collection
# Save short Url and url
# The short Url is stored as index as all looks
# find and deletes will be only using short Url
def saveUrl(self, shortUrl, url):
saveQuery = {'_id': shortUrl, 'url':url}
try:
self.collection.insert_one(saveQuery)
except:
return False
return True
In the above code, the shortURL is kept as index as all operations in the database is going to be performed in most of the case and its required to be unique.Hence it makes a wonderful unique key to index the database.
So we write a unit test to check that the code works properly as below
class TestUrlShortener(unittest.TestCase):
def setUp(self):
connection = pymongo.MongoClient('mongodb://localhost:27017/')
self.database = connection.test
self.collection = self.database.urlshortener
self.urlShortener = urlShortener(self.collection)
def test_saveUrl_Unique(self):
# setup
url = "http://www.google.com"
shortUrl = "gl"
result = self.urlShortener.saveUrl(shortUrl, url)
# Assertions
self.assertEqual(result, True)
doc = self.collection.find_one({'_id': shortUrl})
self.assertEqual(doc, {'_id': shortUrl, 'url': url})
# cleanup so that next time we dont get duplicateKeyError
self.collection.delete_one({'_id': shortUrl})
def test_saveUrl_duplicate(self):
shortUrl = 'orig'
url = 'http://www.google.com'
urldup = 'http://www.yahoo.com'
self.urlShortener.saveUrl(shortUrl, url)
result = self.urlShortener.saveUrl(shortUrl, urldup)
self.assertEqual(result, False)
doc = self.collection.find_one({'_id': shortUrl})
self.assertEqual(doc, {'_id': shortUrl, 'url': url})
self.collection.delete_one({'_id': shortUrl})
Now that we have methods to save, the next important method is findURL from the database. The code is simple
# Finds a url from shorUrl that is sent from the user
def findUrl(self, shortUrl):
try:
doc = self.collection.find_one({'_id': shortUrl})
except:
return None
if doc is None:
return None
return doc['url']
When the database cannot find a short URL we must send a NotFound message.
And finally methods for deleting and generating a alpha numerical code of fixed length for short URL as below
def removeUrl(self, shortUrl):
try:
result = self.collection.delete_one({'_id': shortUrl})
except:
# we would want to log an error message as of now
return False
return True
# generates an shorturl needed from so
# http://stackoverflow.com/questions/2257441/random-string-generation-with-upper-case-letters-and-digits-in-python/23728630#23728630
def generateShortUrl(self, length=6):
return ''.join(random.SystemRandom().choice(string.ascii_uppercase + string.digits) for _ in range(length))
We can always run the test code at any time using the below command at top level
python -m unittest discover
Finally we create a mongodbHandler.py to handle all the connection information for url Handler. The code is as follows
import pymongo
import os
# TODO: Make this class read from a config file
# Now it reads from the enviornment variable
class MongoDatabaseHandler:
def __init__(self):
connection_string = os.environ['CONNECTION_STRING']
self.connection = pymongo.MongoClient(connection_string)
self.database = self.connection.urlshortener
def get_ShortURLCollection(self):
return self.database.shorturls
The above code reads from enviornment variable CONNECTION_STRING, make sure that your export it in your shell as export CONNECTION_STRING = "mongodb://localhost:27017/"
Designing of the web page(View)
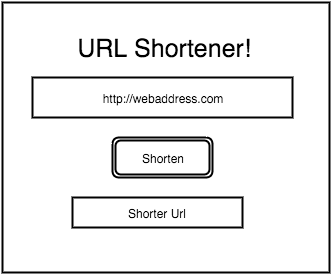
Now that we have got the basic structure of the backend all taken care, we can look designing the front end. I wanted the page to be simple and so i created a basic mockup as follows.
1.The basic web page design in our case is very simple.All we need to do is have a webform that takes an URL and a submit button.
The html front end is divided into 2 parts, the basic include stuff like header that is common between all pages that we are planning to create and the page specific sections. The basic form is as follows
<html><head>
{% if title %}
<title>{{ title }} - URLShortener</title>
{% else %}
<title>Welcome to URLShortener</title>
{% endif %}
</head><body>
{% block content %}
{% endblock %}
</body></html>
3.The landing page (also called the index.html) which we had a UI design above is as follows
The above code sends a post method to the link /UrlShorten, where we will have a handler that will recieve the url value from the form and create a response with the shorturl.
Also you will find the code contains a conditional include shortURL which we will use to send the output.
Handling of requests (Controller)
The final part we need to design the controller which is responsible for handling requests and sending the response.
When a user enters the site, we provide him with the index.html page. so to render the page we have the code as below
from app import app
from flask import render_template
@app.route('/')
@app.route('/index')
def index():
return render_template('index.html')
In the above @app.route which is a decorator provided by the Flask framework to define functions that should handle when browser sends requests.
Now on the handler that redirects the shortened url to the full url. The code is simple, it just reads from the database using the shortened url as the key.If a page is found it redirects to that page or it sends a 404 not found code.
@app.route('/<shorturl>')
def getURL(shorturl):
url_shortener_handler = urlShortener()
url = url_shortener_handler.findUrl(shorturl)
app.logger.debug("value of url(%s) is for short url(%s) ", url, shorturl)
if url is not None:
return redirect(url, code=302)
else:
return abort(404)
Finally the controller handler which generates creates the shortURL is as follows
@app.route('/UrlShorten', methods=['POST', 'GET'])
def shortenUrl():
if request.method == 'POST':
url = request.form['url']
url_shortener_handler = urlShortener()
#TODO have a mechanism for handling duplicate key error
short_url = url_shortener_handler.generateShortUrl()
if url_shortener_handler.saveUrl(short_url, url):
# TODO move the site_prefix to a config file
site_url = os.environ['SITE_URL']
return render_template('index.html', shortURL=site_url+short_url)
else:
#TODO change this to temporary error message
return render_template('index.html', shortURL=None)
else:
return redirect('/')
In case of web form submission, the code just creates a instance of the UrlShortener that handles all the backend storage and if there is an error in generation of short URL it just redirects to homepage.
Also, we are importing a global variable called ‘SITE_URL’ which is needed as site prefix in the short url generation.For testing locally export SITE_URL="http://localhost:5000/"
I wanted to play around with python more in terms of web application, rather than a scripting language.So i decided to create a URL shortener to understand the frameworks better. I chose flask because its a simpler framework than Django and is well supported.
Here are the steps i followed
Setting up the enviornment.
Create a folder for my project
mkdir UrlShortener
I wanted to use a virtual env as it helps managing dependencies better.
Pradheep github $ cd UrlShortener/
Pradheep UrlShortener $ virtualenv venv
New python executable in venv/bin/python2.7
Also creating executable in venv/bin/python
Installing setuptools, pip, wheel...done.
Now we have all the virtual enviornment all set and ready to go.
Finally i activate the virtual enviornment by using activate command as follows
I looked up this micro blog for some ideas and basic structure of the flask application. I wish i would write a full blown application like the author and i highly recommend reading the blog
write concern dictates if the mongodb client must wait for the mongodb server acknowledgment before it starts executing the next instruction.
Journal is analogus to the transcation log in sql database that needs to be persisted for durability.
The default configuration of the mongodb is w=1, j= false, which means that mongodb client waits for acknowlegnment from the server that the transcation is successful before continuing processing of the next operation.
Since there is no commit to the disk in this scenario there is a small window in between the operation committing to disk and server failure of loss of data.
For strong consistency and for no loss of data the configuration that is suggested is w=1,j=true. However this has a slow performance compared to w=1,j=false as disk access is slow.
The configuration (old one) of setting w=0 is not recommended as the client does not wait for the operation to succeed.This is wrong because when the write fails due to any errors the application will not be able to detect and handle it.
There is a network connection between the mongodb client and mongodb server which can also be the cause of errors due to packet loss or any other network issues.
Solution to the above problem is 2 things. In case of insert we need not worry about it as the retry from the client side would cause a duplicate key error and handling this is simple.
The problem occurs in cases where update is used on part of the document especially with Inc and dec operands. In this case its harder to handle as we are not sure what the new value must be.
In case of replication, mongodb supports 3 types of node
a. Regular node - It acts as secondary node, that can act as a primary node in case of primary failure.
b. Arbirter - It just participate in election, casts votes and does not store data.Advantage is that is that its not resource hungry and used for testing.
c. Delayed/Regular - It is mostly used as a backup node, usually hours behind.Priority is set as zero so that it cannot become primary.
d.Hidden node - Used for analytics and has voting rights. Priority set to zero as it does not want to become primary.
For majority to happen, there should be at least 3 nodes that must cast a vote to select one as leader.In case of node failure, the nodes the other nodes hold an election and the node that contains the maximum oplog(transaction log) will become a leader.
By default all reads and writes are made from the primary node, so the data is strongly consistent.
We can configure data to be read from secondary, hence it the reads from the secondary may not be same what is at the primary.
The mongodb replication are replicated asynchronously from the primary to all the secondaries.
Reading from the secondary,means that the load is lesser than primary and it means we can balance some load.Its possible to make all data read and write of a particular database to primary and reading from load balancing to secondary for other database.
Replica sets are created using the following commands in mongo shell
mongod --replSet <replicaName>
all nodes of replication set must have the same relicaName.
** rs.initiate() **, ** rs.status() ** command can be used to initiate a replica set and show the the status of a replica set respectively.
** rs.slaveOK() ** command must be used to allow reading from secondary node.
19.During election reads and writes are not allowed till election happens and a new primary is elected.
20.The oplog which records all operations and which is used for replication can be seen using
use local
db.rs.oplog.find()
The oplog is a capped collection which means if the network is slow or the database operations is replicated slowly because the secondary is a slower box, then there could be loss of data.
In case of secondary misses the oplog, then it restart the reading of entire database from primary and this is going to be a slow process.
The mongodb drivers are intelligent and once you given a valid node, it will detect all other nodes in replica set and failover to the new primary if needed automatically.
To handle the case of fail over during an insert is performed, one needs to handle 2 errors that are thrown by the mongodb client library
pymongo.errors.AutoReconnect - Thrown when a client reconnects to a new primary
To handle this case , the library must have a reconnect mechanism to make sure that we retry for n times. When we retry to insert, then we must insert get a duplicate key error since the network may have disconnected before the response to client.
for i in range(0,500):
for retry in range (3):
try:
things.insert_one({'_id':i})
print "Inserted Document: " + str(i)
time.sleep(.1)
break
except pymongo.errors.AutoReconnect as e:
print "Exception ",type(e), e
print "Retrying.."
time.sleep(5)
except pymongo.errors.DuplicateKeyError as e:
print "duplicate..but it worked"
break
Note the above is not perfect as it might not work when the election takes more than 14 seconds.
25.In case of read, we should keep on retrying read and we need not worry about duplicate key error as we are just reading and not writing.
for i in range(0,500):
for retry in range (3):
try:
things.find_one({'_id':i})
print "read document: " + str(i)
time.sleep(.1)
break
except pymongo.errors.AutoReconnect as e:
print "Exception ",type(e), e
print "Retrying.."
time.sleep(5)
26.update is kind of tricky in case of non idopotent cases like $push , $inc $dec since when we retry the values it might have been incremented already.
for i in xrange(500):
time.sleep(.1) # Don't want this to go too fast.
for retry in xrange(3):
try: # to read the doc up to 3 times.
votes = things.find_one({'_id': i})["votes"] + 1
break
except pymongo.errors.AutoReconnect as e: # failover!
print ("Exception reading doc with _id = {_id}. " +
"{te}: {e}").format(_id=i, te=type(e), e=e)
print "Retrying..."
time.sleep(5)
else:
print "Unable to read from the database. Aborting."
exit()
for retry in xrange(3):
try: # to read the doc up to 3 times.
things.update_one({'_id': i}, {'$set': {'votes': votes}})
print "Updated Document with _id = {_id}".format(_id=i)
break
except pymongo.errors.AutoReconnect as e: # failover!
print ("Exception writing doc with _id = {_id}. " +
"{te}: {e}").format(_id=i, te=type(e), e=e)
print "Retrying..."
time.sleep(5)
else: # If no break, we failed to write the document. Abort.
print ("We have failed to increment the 'votes' field for " +
"the document with _id = {_id} to {votes}. Exiting."
).format(_id=i, votes=votes)
exit()
This leads to 2 ways to handle these cases
1. If the value is very important that the data to be correct then we must convert the insert from inc to a read operation and then increment the value and write the new value to the database.
Note: In this case, if you application has multiple threads, then one thread you could have thread races and result in data loss between the increments in threads.Locks could be a solution in application but it can be a problem if your application is distributed.
2. If its okay for value to be a little bit more or less from application perspective then we can either decide to retry in the AutoReconnect error scenario or we could ignore the error altogether and retry(not a good one since we might start losing values)
The write concern for a mongodb replica can be set at database level, collection level or connection level, the values can be set to an ** integer ** (denotes the number of nodes to write to before acknowledging) or ** majority **
Specifying ** majority ** is preferred as it prevents loss of data due to secondaries not in sync. Of course there is a increase in response time waiting for acknowlegement for the majority of nodes.
** Wtimeout ** can be used to specify the maximum time the server must wait for majority of time the client must wait for acknowledgement.
Read preference can be used to specify which node that the client must read from. The following are the options supported.
1.Primary - Default - read only from primary node.
2.Primary Preffered - Reads from secondary if primary is not available.
3.Secondary - Reads from secondary only
4.SecondaryPreffered -Reads from primary if no secondary is available.
5.Nearest - The node thats nearest to the client.
sharding
We shard to achieve horizontal scalability i.e. we make sure that there not only one server is able to handle all load but its distributed across servers
Each shard is a replica set itself which means each replica set is highly available.
In order to ensure unique key across replica each unique index must contain shard key.
Shard keys must be used in all queries else the mongos will send the queries to all shared sets and provide the aggregated result.
On sharding, the client libraries(drivers) connect to the mongos which is responsible for figuring which shred that the operation must be sent to.
Mongos are lightweight and usually deployed in the same application server and its possible to have multiple mongos running for high availability.